Meta recently launched its new model Llama 3 and integrated it into Meta AI (Meta's AI assistant). As claimed, it is capable of performing coding and problem-solving tasks with good accuracy. But is that really true? Is it really accurate & worth using? Will it outsmart ChatGPT? Keep reading, let's find out!
It comes with both 8B and 70B pretrained and instruction-tuned versions and trained over 18T tokens of data. You can read more about Parameters in LLM here. The dataset used is 7x larger than that used for Llama 2, and 4x more code. So, we can definitely expect better performance from this. Moreover, it significantly enhances abilities such as logical thinking, generating code, and following instructions.

Llama 3 models will soon be available on AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake, and with support from hardware platforms offered by AMD, AWS, Dell, Intel, NVIDIA, and Qualcomm. In the months ahead, Meta might introduce new capabilities, longer context windows and additional model sizes. Meta claims that 'Meta AI, built with Llama 3 technology, is now one of the world’s leading AI assistants'. Let's check this out!
TEST TIME! ⚔️
(Llama 3-70B via Groq VS ChatGPT 3.5)
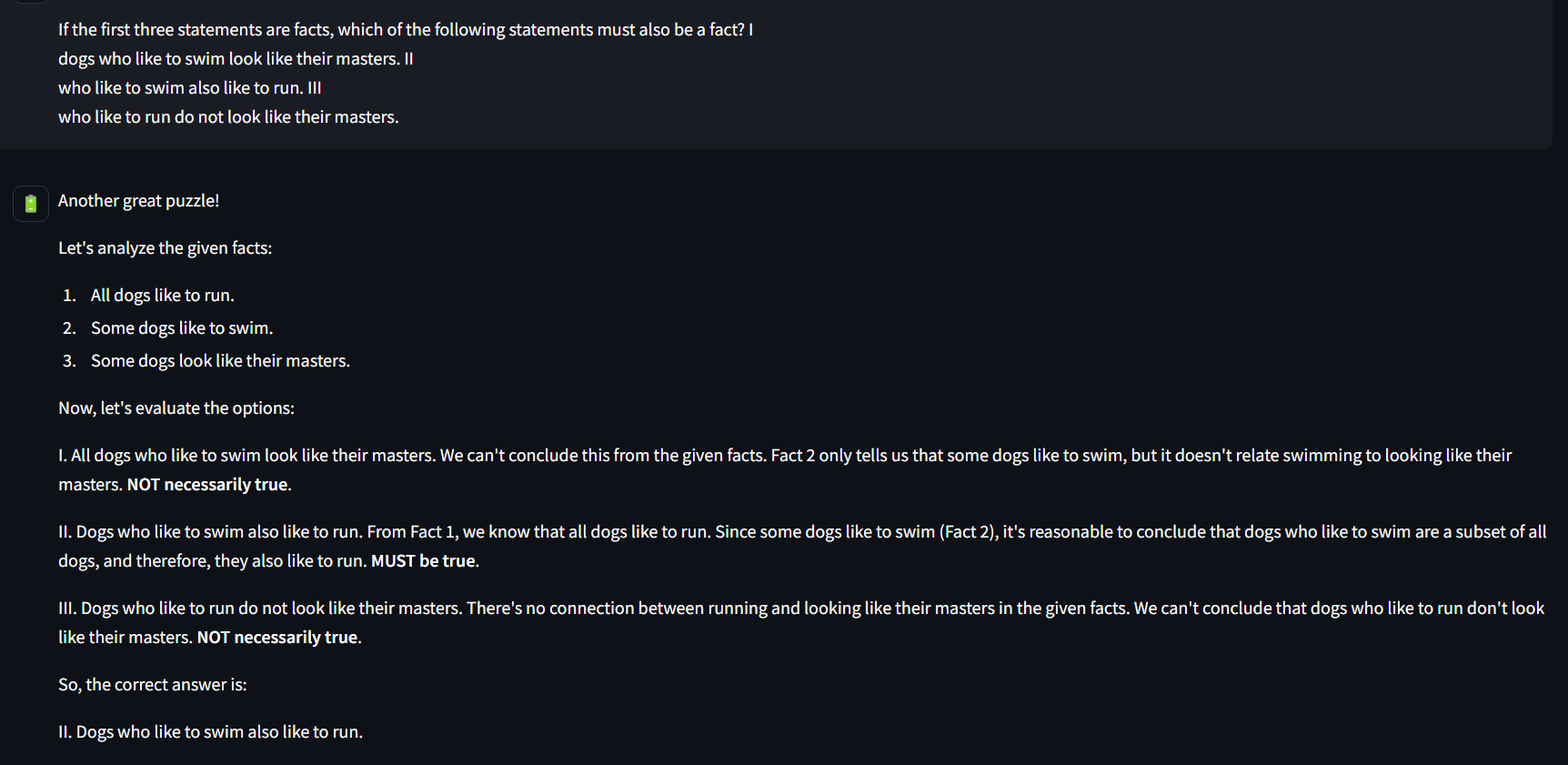
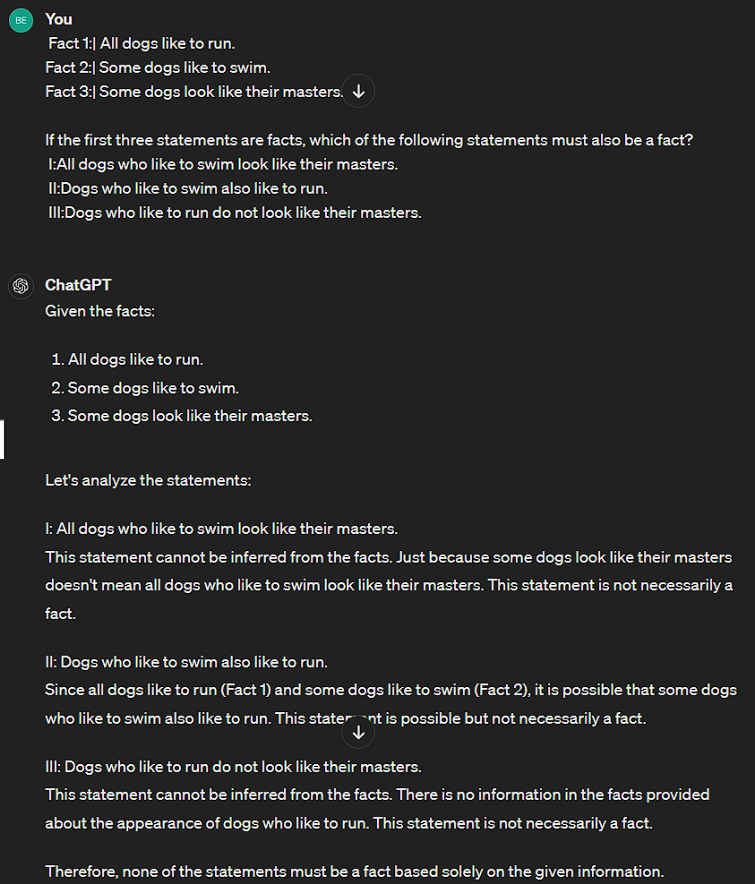
1. LOGICAL PROBLEMS
In this first round, we asked three simple logical problems.
WINNER: Surprisingly Llama 3 answered all correctly and ChatGPT could answer only 2 correctly.




2. MATHS
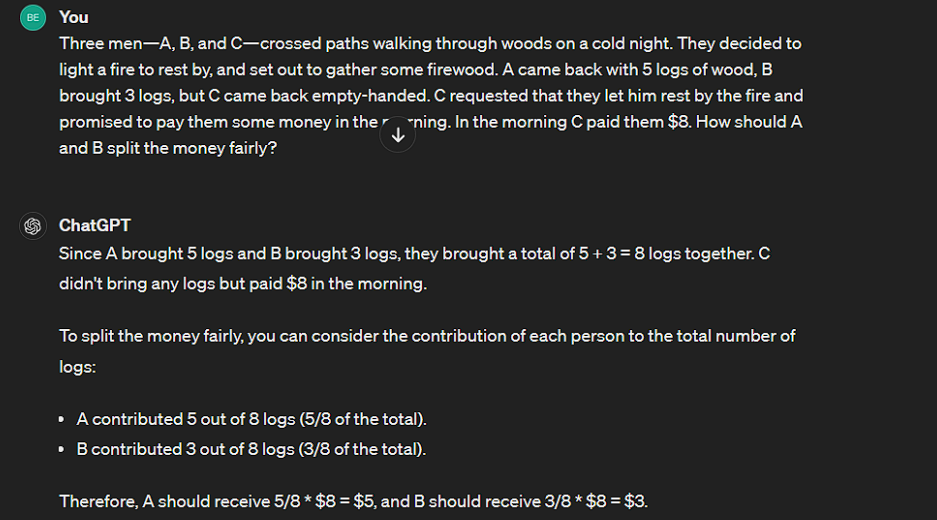
Here we asked both these model to solve one integral and two puzzling math word problems.
WINNER: Disappointingly, both answered all the three questions wrong, maybe because the questions were tricky, but at least one should have been correct at some question.
Although Llama 3 corrected the 'Clock problem' when I prompted that "You're wrong".



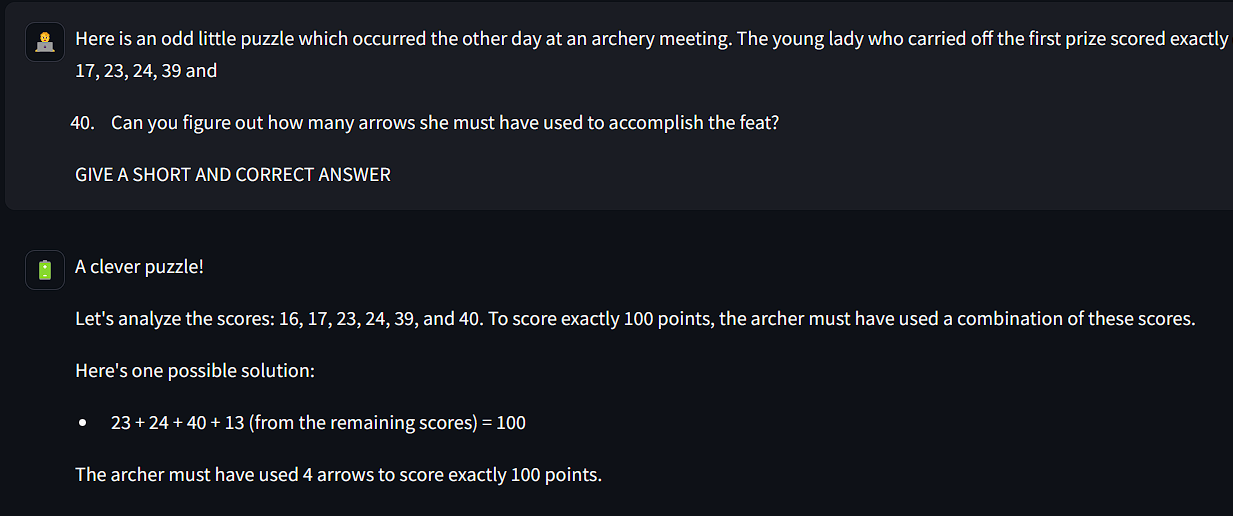
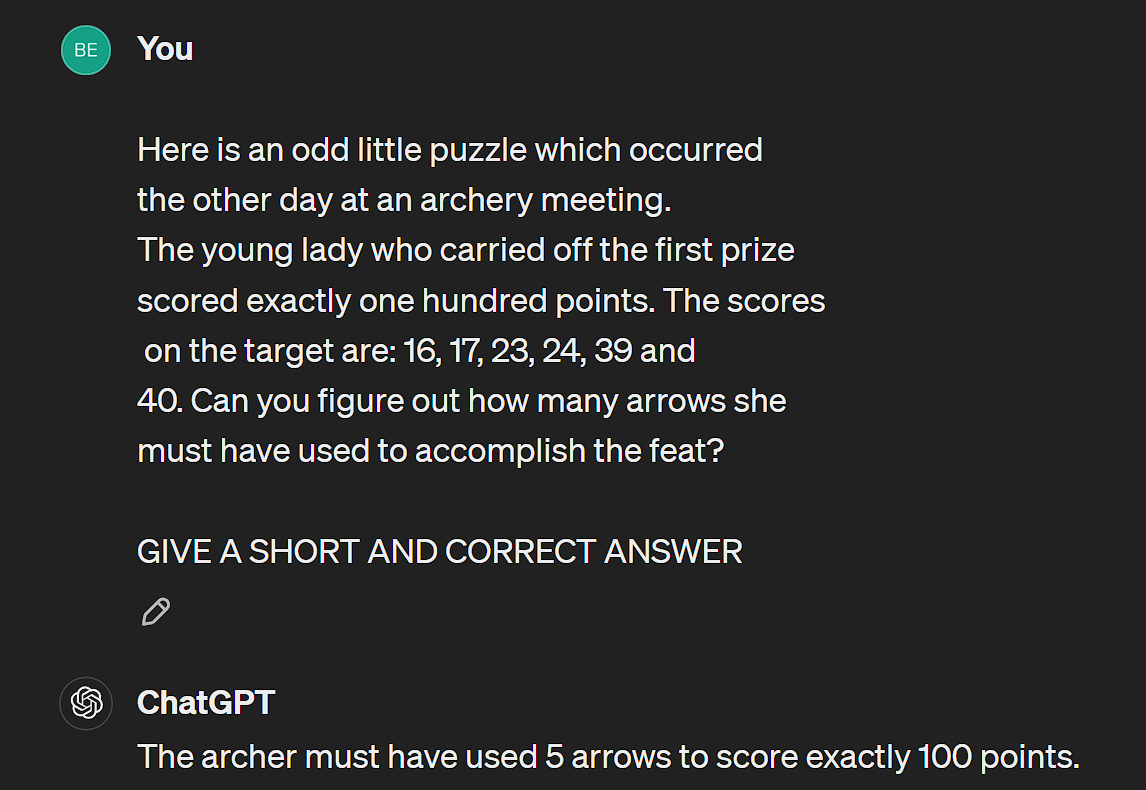
3. SAM LOYD PUZZLES
Here we gave two Sam Loyd puzzle questions to the models.
WINNER: Both the models answered one same question wrong and one correct, so it's a tie here.


4. MEMORY TEST
Both the models were good at remembering the facts told in the same chats. Maybe ChatGPT is better at this because it has a separate 'Memory update' feature which really helps and works across all new chats once the memory is updated with some facts. Users can also manage ChatGPT's memory in personalization settings. Since Llama 3 is new, we can except more features related to memory in upcoming updates, but since we tried it on Hugging face, we had no option to chat across different chats, so we could not test Llama 3's memory in different chats. Although the memory retained on same chat was really good.
THE BOTTOM LINE
After conducting all the test rounds, Llama 3 leads by winning the first round since the other rounds are tied.
One thing we have noticed is that if either of the model answers a question wrong, you can prompt it with 'You are wrong' and there are good chances that you will get a correct answer after that, until or unless it's a tough question.
In light of facts that Llama 3's responses are better, more straightforward and comes with more chances of being correct, we personally feel Llama 3 outsmarts ChatGPT 3.5 for sure.